Моніторинг даних та попередня обробка
Набір даних про моніторинг включає 300 репрезентативних вимірювань деформації, зібраних у різних методах будівництва та моніторингу під час будівництва тунелю G, що охоплює з квітня 2022 по березень 2023 року. Джерела даних узагальнені в таблиці 1.
Наявність переживань у даних моніторингу може негативно вплинути на точність тренувань моделі, зменшити можливість узагальнення та погіршити якість пристосування даних. Тому попередня обробка зменшення шуму є важливою. У цьому дослідженні метод квадратичного експоненціального згладжування – аналіз часових рядів та методика прогнозування – застосовується для попереднього процесу даних. Цей метод присвоює більшу вагу більш новим точкам даних та меншими вагами для старих, тим самим ефективно зменшуючи шум.
Рівняння наведені в рівнянні. (26) та (27):
$$ \: {f} _ {t} = \ alpha \: {\ cdot} \: {y} _ {t}+{l} _ {t-1} {\ cdot} \ 🙁 1- \ alpha \:) $$
(26)
$$ \: {l} _ {t} = \ alpha \: {\ cdot} \: {y} _ {t}+{l} _ {t-1} {\ cdot} \ 🙁 1- \ alpha \:) $$
(27)
де, Fт це передбачуване значення в цей момент; \ (\: \ alpha \: \) – параметр згладжування, [0,1]; Ут є спостережуваним значенням на мить т; ЛТ-1 – спостережуване значення в попередній момент; Лейтенант є горизонтальним значенням на мить т.
Дані моніторингу нормалізуються та лінійно масштабуються в діапазоні [0, 1]. Формула нормалізації представлена у рівнянні. (28).
$$ \: {x} _ {n} = \ frac {x- {x} _ {min}} {{x} _ {max}-{x} _ {min}} $$
(28)
Де, X є початковим значенням; Xп. – нормалізоване власне значення; Xмаксимум – початкове максимальне значення; Xхв – початкове мінімальне значення.
Щоб запобігти перенапруженням та покращити узагальнення та стабільність моделі, нормалізований набір даних поділяється на підмножини з навчання та тестування відповідно до заздалегідь визначеного співвідношення. Зокрема, 70% даних виділяються для навчання, тоді як решта 30% використовуються для оцінки можливостей ефективності та узагальнення моделі.
Конструкція моделі глибокого навчання
Архітектури глибокого навчання можна класифікувати на різні типи на основі завдань, типів даних, мережевих структур та інших критеріїв. На основі структури мережі, репрезентативні моделі включають нейронні мережі Feedforward (FNN), CNN, RNN, генеративні змагальні мережі (GAN), Graph Neural Networks (GNN) та механізми уваги. Характеристики та сценарії застосування різних нейронних мереж – таких як CNN, RNN, GAN, GNN та механізми уваги – значно скорочуються, як узагальнено в таблиці 2.
У цій роботі в першу чергу використовуються моделі глибокого навчання, такі як RNN, LSTM, GRU та CNN-GRU, та основні кроки для побудови цих моделей викладені нижче.
Програмування попередньої обробки даних та модельного тренувального трубопроводу можна узагальнити наступним чином: По-перше, підготовка даних передбачає збір представників, високоякісних наборів даних, видалення зайвих або галасливих записів та вилучення відповідних багатовимірних функцій. Далі застосовується нормалізація даних для того, щоб забезпечити вхідні функції на порівнянних масштабах. Потім вибирається та розроблена відповідна архітектура моделі на основі конкретних вимог завдань. Для сприяння ефективному навчанню вибираються відповідні функції активації, функції втрат та оптимізатори. Згодом набір даних поділяється на підмножини навчання, валідації та тесту відповідно до типу завдання, а для прискорення конвергенції використовується міні-пакетна підготовка. Під час компіляції та навчання моделі налаштовані такі параметри, як швидкість навчання, розмір партії та кількість епох. Навчальний процес контролюється за допомогою функцій втрат та показників оцінювання для запобігання перенапруження. Потім модель оцінюється на тестовому наборі за допомогою різних показників, а для оцінки її ефективності побудовані криві втрати та точності. Нарешті, продуктивність моделі та узагальнення додатково вдосконалюються шляхом вдосконалення архітектури, налаштування гіперпараметрів, вибору відповідних оптимізаторів та застосування методів регуляризації.
Конструкція моделі глибокого навчання, поєднуючи біонічні алгоритми
Біонічні алгоритми – це методи оптимізації, які вирішують практичні проблеми, імітуючи біологічні процеси, еволюційні механізми або екологічну поведінку, що спостерігаються в природі. Їх основним принципом є повторити поведінку, еволюційні закономірності та адаптаційні стратегії організмів у природі для виявлення оптимальних або майже оптимальних рішень.
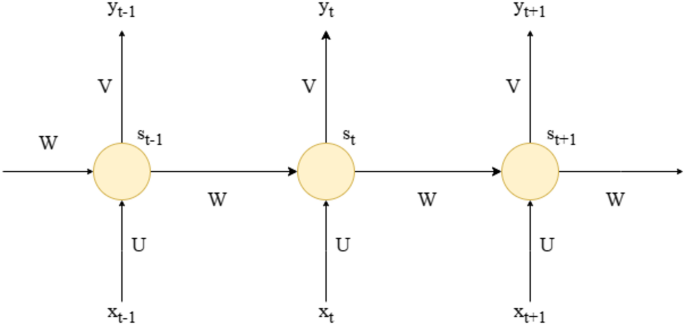
Крок 1: Створіть набір даних часових рядів, розділивши дані на вхідні послідовності та їх відповідні цільові значення. Використовуйте функцію NP.Reshape, щоб додати тимчасовий вимір, перетворюючи дані з “(кількість зразків, кількість функцій)” на “(кількість зразків, кількість функцій, кількість часових кроків)” для задоволення вхідних вимог моделі CNN-GRU.
Крок 2: Імпортуйте послідовну модель з бібліотеки Керас, налаштуйте мережеві параметри, такі як кількість конволюційних ядер, розмір ядра та функція активації, а також застосовувати нульовий клапан для підтримки послідовних розмірів введення та виводу, тим самим створюючи модель CNN-GRU.
Крок 3: Оцініть поточне рішення шляхом навчання моделі, регулюючи кількість вузлів нейронів у шару GRU, встановлюючи функцію активації та обчислення помилки між виходом моделі та значенням моніторингу. Використовуйте формулу градієнта спуску, щоб оновити ваги, перевіряючи, чи відповідають максимальна кількість ітерації (200) або вимоги до точності. Якщо ні, продовжуйте навчання; В іншому випадку зупиніться і зберегти оптимальну матрицю ваги. Потім передайте повну послідовність до повністю підключеного шару. Нарешті, навчіть модель за допомогою оптимізатора Адама та оцініть точність, використовуючи функцію втрати середньої квадратної помилки (MSE).
Крок 4: Визначте алгоритм оптимізації китів (WOA) та використовуйте його для оптимізації гіперпараметрів або ваг моделі. Потім навчіть остаточну модель CNN-GRU за допомогою оптимізованих WOA параметрів та оцініть продуктивність моделі шляхом моніторингу функції втрати та точності.
Крок 5: Після завершення тренувань, заощаджуйте оптимальні ваги моделі для подальшого використання.
Показники для оцінки ефективності прогнозування
У цьому документі використовується помилка середньої квадрата кореня (RMSE) та середня абсолютна відсоткова помилка (MAPE) як індикатори для вимірювання помилки між передбачуваними та фактичними значеннями. RMSE має ту саму одиницю, що і початкове цільове значення, що полегшує порівняння, тоді як MAPE вимірює відносну помилку. Тому RMSE та MAPE вибираються в якості показників оцінки для продуктивності моделі, при цьому формули обчислення показані в рівнянні. (29) та (30).
$$ \: rmse = {\ ліворуч[\frac{1}{n}\left(\sum\:_{i=1}^{n}{\left(y-\widehat{y}\right)}^{2}\right)\right]}^{\ frac {1} {2}} $$
(29)
$$ \: mape = \ ліворуч (\ frac {1} {n} {\ sum \:} _ {i = 1}^{n} \ frac {\ left | y- \ widehat {y} \ right |} {y} \ right) \ times \: 100 \%$$ $ $ \: 100 \%$$ $ $ $ \: 100 \%$$ $ $
(30)
Де, п. – загальна кількість зразків; у є фактичним значенням ІТ зразок; \ (\: \ widehat {y} \) це передбачуване значення ІТ зразок.
Вибір параметрів моделі порівняння
Для оцінки прогнозної ефективності моделі WOA-CNN-GRU для моніторингу конструкції у високошвидкісних залізничних тунелях, це дослідження порівнює його результати з результатами чотирьох моделей нейронної мережі: RNN, LSTM, GRU та CNN-GRU. Налаштування параметрів як для базових моделей, так і для моделі WOA-CNN-GRU наведені в таблиці 3.
Конструкція моделі глибокого навчання
Аналіз точності моделі
Набір даних про поселення поверхні DK24 + 985: Z1, зібраний із розділу Метод, використовується як вхідні дані для оцінки точності навчання різних моделей. Спочатку навчальний набір даних подається на п'ять моделей-RNN, LSTM, GRU, CNN-GRU та WOA-CNN-GRU-щоб порівняти свої навчальні показники. Результати тренувань кожної моделі представлені на рис. 11, тоді як відповідні криві функції втрат проілюстровані на рис. 12. Як показано на рис. 11 і 12, всі моделі досягають точності прогнозування, що перевищує 95%, коли застосовується до прогнозування поверхневого розрахунку в секції кроку. Це вказує на те, що хоча всі моделі демонструють потужні продуктивність, все ще існують варіації точності.
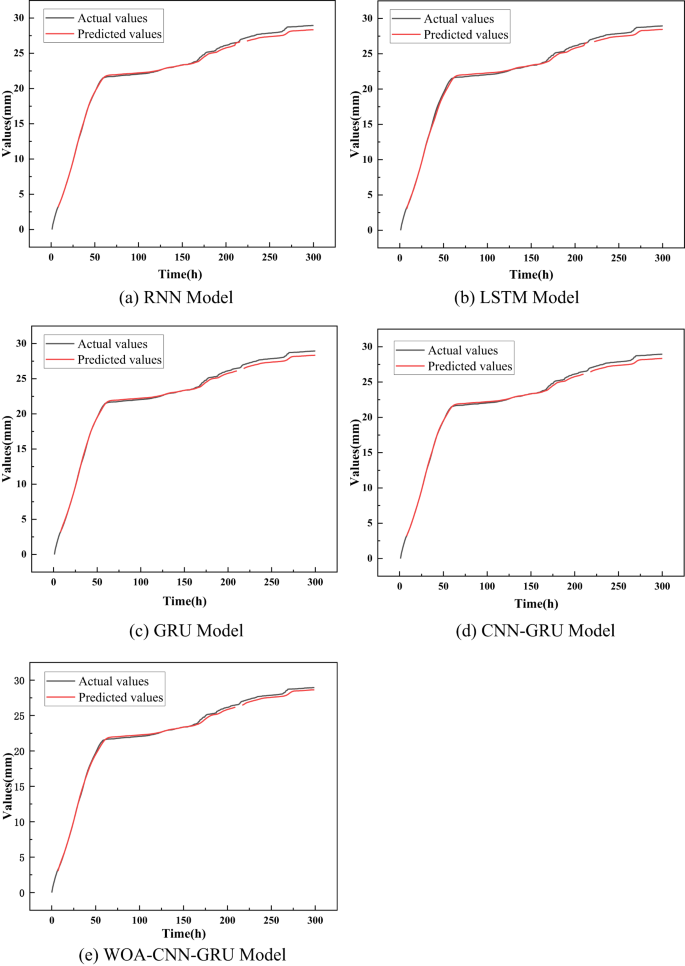
Результати тренувань різних моделей.
Як показано на рис. 11 і 12 та узагальнені в таблиці 4, модель WOA-CNN-GRU досягає RMSE 0,1257 мм для прогнозування деформації будівництва у високошвидкісних залізничних тунелях. Для порівняння, значення RMSE для моделей RNN, LSTM, GRU та CNN-GRU становлять 0,9814 мм, 0,7629 мм, 0,4188 мм та 0,2292 мм відповідно. Модель також дає MAPE 0,51%, тоді як відповідні значення для моделей RNN, LSTM, GRU та CNN-GRU становлять 2,64%, 1,37%, 1,05%та 0,86%відповідно. Більше того, модель WOA-CNN-GRU демонструє найнижчі втрати тестування та валідації при 0,8 × 10⁻⁵ та 2,1 × 10⁻⁵ відповідно. На відміну від цього, інші моделі дають значно більші значення для цих показників.
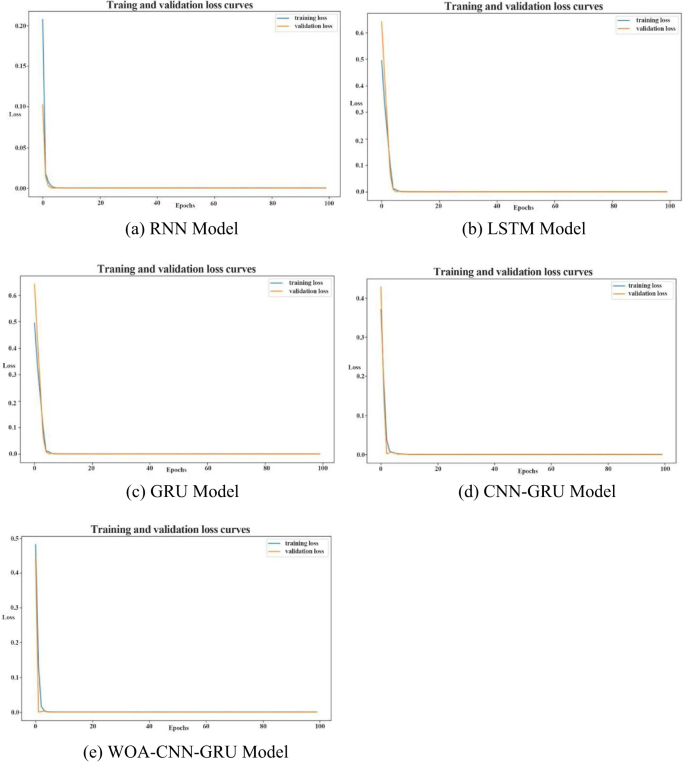
Функція втрат для різних тренувань моделі прогнозування.
Абсолютна точність прогнозування моделі покращується за факторами 6,8, 5,1, 2,3 та 0,8 порівняно з моделями RNN, LSTM, GRU та CNN-GRU відповідно. Аналогічно, його відносна точність прогнозування збільшується за факторами 4,2, 1,7, 1,1 та 0,7. Ці результати демонструють, що оптимізована WOA-модель CNN-GRU значно перевершує звичайні моделі глибокого навчання з точки зору прогнозної продуктивності. Тому модель WOA-CNN-GRU може точно прогнозувати поселення поверхні та горизонтальну конвергенцію в конструкції тунелю, тим самим сприяючи покращенню безпеки в інженерії високошвидкісних залізничних тунелів.
Аналіз точності моделі
Навчена модель WOA-CNN-GRU застосовується до різних методів роботи, розділів та даних моніторингу, порівняння між передбачуваними та фактичними значеннями, показаними на рис. 13.
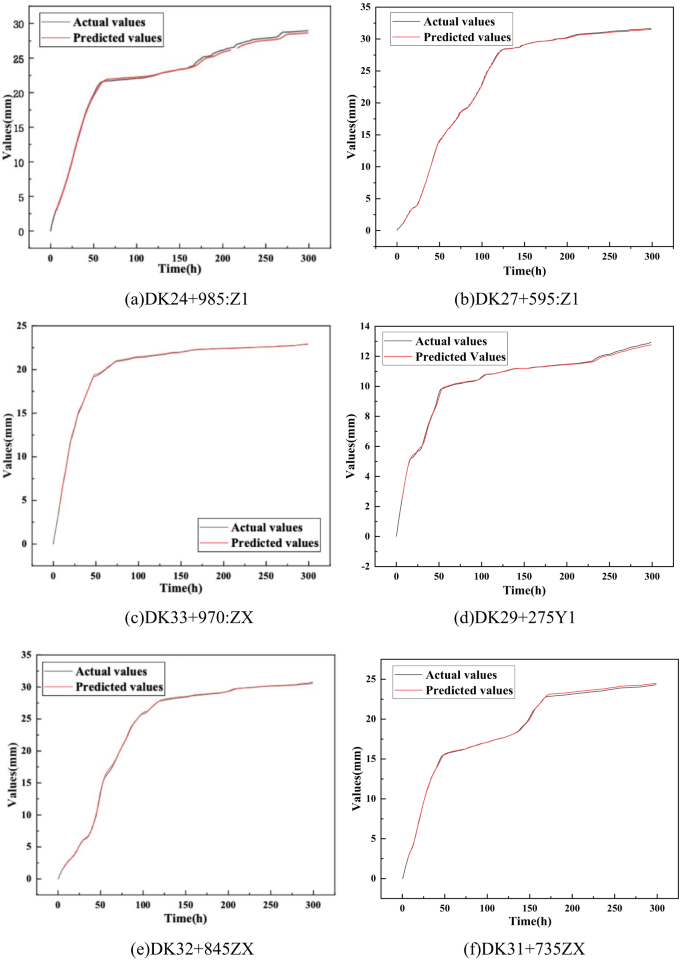
Порівняння фактичних та прогнозованих значень для різних даних моніторингу.
Як показано на рис. 13; Таблиця 5, RMSE та MAPE між фактичними та передбачуваними даними моніторингу в різних джерелах під час високошвидкісного будівництва залізничних тунелів постійно нижче 1 мм та 1%відповідно. Ці результати свідчать про те, що модель WOA-CNN-GRU є високоефективною та надійною для прогнозування навколишньої деформації гірських порід. Його застосування може сприяти підвищенню ефективності будівництва та зменшенням витрат на проект.