






Вивчення населення
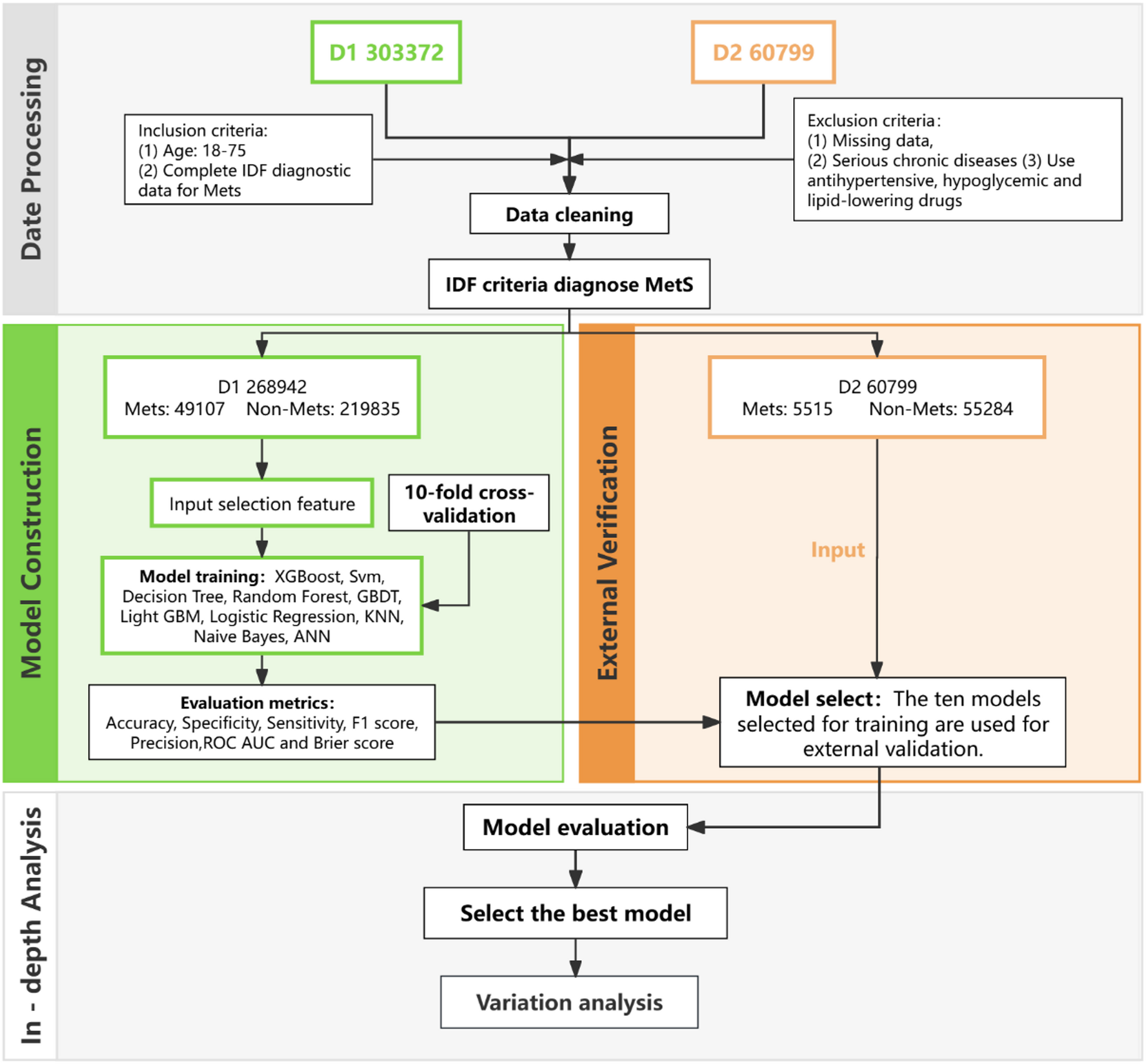
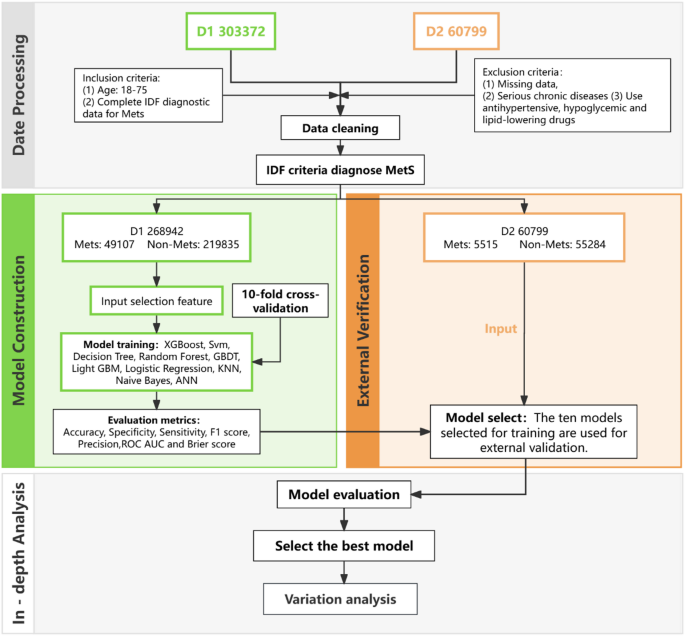
Наше дослідження використовує набір даних, що включає 303 372 осіб, які проводили обстеження в галузі охорони здоров’я в медичному центрі медичного медичного медичного медичного медичного медицини третьої лікарні Центрального Південного університету з 2017 по 2022 рік. Це ретроспективне дослідження, призначене D1, було затверджено Комітетом з етики лікарні та дотримувалося декларації Гельсінкі. Учасники надали свою інформовану згоду. Дані були отримані з системи електронних медичних записів лікарні та використовувались для навчання та перевірки нашої прогнозної моделі для METS.
Для набору даних D2, щоб оцінити узагальненість нашої моделі, ми включили зовнішній набір перевірки, D2. Цей набір був отриманий з поперечного дослідження робочого населення на Балеарських островах, Іспанія, яке було проведено між 2012 та 2016 роками. Набору даних, до якого можна отримати доступ через https://datadryad.org/stash/dataset/doi:10.5061/dryad.cb51t54, [17]охоплює 60 799 учасників у віці від 20 до 70 років, що представляє різноманітні сектори, такі як державне управління та медичні послуги. У дослідженні було запрошено 69 581 працівників, а 60 799 (припадає на 10,2% активного населення), 57,3% – чоловіки, а 42,7% – жінки. Блок -схема представлена в (рис. 1).
Огляд методів дослідження
Процедури збору даних
Для набору даних D1 підготовлений медичний персонал проводив інтерв'ю для здоров'я та зібрав демографічну та поведінкову інформацію, таку як вік, стать, історія хвороби та деталі будь -яких ліків, які використовуються. Зразки крові голодування аналізували для визначення рівня глюкози в крові натще (FBG), тригліцериду (ТГ) та ліпопротеїнового холестерину високої щільності (ЛПВЩ-С) за допомогою специфічного аналізатора (називають Cobas 8000). Кров'яний тиск вимірювали за допомогою певного пристрою (OMRON) після стандартизованого протоколу. Антропометричні вимірювання проводилися за стандартами, встановленими ISAK.
For the D2 dataset, health information was collected, including ID, age, sex, smoking status, body fat percentage (BF), body shape index (ABSI), BMI, WC, waist-to-height ratio (WHtR), noninsulin-dependent diabetes (NIM), systolic (SBP) and diastolic (DBP) blood pressures, total cholesterol (TC), LDL-C, HDL-C, Рівень глюкози (GLU) та TG.
Очищення та обробка даних
Очищення даних D1
Ми ініціювали всебічний процес очищення даних від початкових 303,372 учасників. Критеріями включення були дорослі у віці 18–75 років з наявними даними про туалет, окружність стегна, артеріальний тиск, частоту серцевих скорочень та вік. Критерії виключення охоплювали ті, хто має відсутні дані, важкі хронічні захворювання, такі як рак, кінцева стадія ниркової хвороби або важкі захворювання серця, а також ті, що мають антигіпертензивні або ліпідні ліки, щоб зменшити упередження діагностики METS. Це призвело до остаточного зразка з 268 942 учасників. Вони були класифіковані як Метс або ні на основі критеріїв IDF [18] (Рис. 2)з 49107 визначеними як Метс і 219 835 без.

Міжнародна федерація діабету (IDF) Діагностичні критерії метаболічного синдрому
D2 Обробка даних
Набір даних D2, спочатку діагностований критеріями NCEP-ATP III, був переоцінений за допомогою стандартів IDF для послідовного діагностичного порівняння. Ми застосували європейські пороги WC (≥ 94 см для самців та ≥ 80 см для жінок). Через WHTR висоту обчислювали, а потім визначали BRI. Після переробки IDF 5515 учасників було визнано Mets, а 55 284 були позначені як контроль, що не є Mets.
Вибір функцій та вилучення
Для раннього виявлення METS ми наголосили на неінвазивних показниках як прогнозних особливостей для скорочення складності та витрат на діагностику. Ми почали з кореляційного та значущого аналізу всіх особливостей кандидата. Використовуючи коефіцієнт кореляції Пірсона для оцінки з'єднання безперервних змінних до METS, ми виявили, що BRI має найсильнішу кореляцію (r= 0,582, С1). WC також мала значну кореляцію і була включена. Висота була додана завдяки своїй ролі в розрахунку BRI. Вік та стать, завдяки їх сильній асоціації з метаболічним здоров’ям, простотою придбання та суттєвими доказами, що свідчать про їх роль у розвитку METS, також були включені до дослідження. Зокрема, поширеність METS збільшується з віком [19, 20]і численні дослідження підтвердили взаємозв'язок між статтю та METS з різними показниками виникнення METS між статями [21]. Як через емпіричний аналіз, так і на статистичні тести, ми гарантували, що ці вибрані риси були статистично значущими та біологічно правдоподібними, що робить їх надійними прогнозами METS. Зрештою, було обрано п’ять змінних (стать, вік, BRI, висота та туалет), при цьому BRI є найціннішим завдяки найсильнішій кореляції з Mets.
Порівняння моделі: машинне навчання проти базової моделі
Для дослідження переваг машинного навчання вперше була побудована проста модель базової лінії на основі діагностичних критеріїв, викладених на рис. 2 (Міжнародна федерація діабету (IDF) для діагностики METS). Ця базова модель класифікувала особи, як позитивні для METS на основі попередньо визначених критеріїв IDF для центрального ожиріння та пов'язаних з ними факторів ризику. Після розробки базової моделі ми продовжили оцінку ефективності десяти алгоритмів машинного навчання. Основна мета полягала в тому, щоб оцінити, чи можуть ці моделі машинного навчання покращити прогнозування MET порівняно з базовою моделлю, яка використовувала заздалегідь визначені діагностичні критерії. The machine learning models employed for this comparison included Logistic Regression (LR), Decision Tree (DT), Random Forest (RF), Extreme Gradient Boosting (XGBoost), Support Vector Machine (SVM), Gradient Boosting Decision Trees (GBDT), Light Gradient Boosting Machine (LightGBM), K-Nearest Neighbors (KNN), Naive Bayes (NB), and Artificial Neural Networks (Енн). Попередня обробка даних та стандартизація були проведені для того, щоб усі моделі були навчені порівнянними даними, з безперервними функціями, стандартизованими за допомогою методу стандартів.
Модель побудова
На основі процесу вибору функцій ми вибрали п'ять ключових особливостей – SEX, AGE, WC, Height та BRI – передбачити зустріч METS. Ми використовували десять алгоритмів машинного навчання, включаючи XGBoost, SVM, DT, RF, GBDT, LightGBM, LR, KNN, NB та Ann. Стандартизація даних проводили за допомогою стандартів для узгодженості. Для забезпечення стійкості та точності моделі ми використовували 10-кратну перехресну перевірку, де дані були розділені на 10 частин, кожна з яких використовувалася для перевірки один раз, а модель була навчана на решті 9 частин. Цей процес повторювали 10 разів. Важливо, що пошук сітки був використаний для оптимізації гіперпараметрів для кожної моделі машинного навчання. Детальні конфігурації параметрів та процедури настройки наведені в додатковому онлайн -вмісті. Дисбаланс класу керував параметром Scale_pos_weight у класифікаторах. Крім того, для подальшого дослідження відносного внеску центральних показників ожиріння (зокрема BRI) для моделювання продуктивності ми провели додатковий аналіз абляції. Враховуючи, що BRI – це складений антропометричний захід, отриманий з туалету та висоти, і служить проксі для центральної ожиріння, ми перекреслили всі моделі після видалення BRI та інших ознак, безпосередньо пов'язаних з центральним ожирінням. Мета полягала в тому, щоб оцінити, чи ці показники однозначно сприяли дискримінації METS поза рештою особливостей.
Оцінка моделі та аналіз порогу
Для оцінки продуктивності моделі на наборі перевірки ми спочатку використовували 50% -ний поріг для класифікації осіб як позитивних для METS на основі прогнозованих ймовірностей. У цьому порізі ми оцінили кілька ключових показників, включаючи точність, точність, відкликання, бал F1, AUC-ROC та бал Brier, для вимірювання продуктивності моделі [22,23,24]. Нижній бал Brier вказує на кращу калібрування.
Далі ми проаналізували поведінку моделі шляхом тестування продуктивності при різних порогах (від 0,1 до 0,9). Це дозволило нам оцінити компроміси між відкликанням, точністю, точністю, специфічністю та балами F1. Відрегулюючи поріг, ми пріоритетували відкликання (мінімізація помилкових негативів) або точність (мінімізація помилкових позитивних даних), що має вирішальне значення для виявлення METS [25, 26].
Модель була навчана за допомогою набору даних D1 та зовнішньо підтверджена набору даних D2 з Балеарських островів, щоб оцінити його узагальненість у різних демографічних показниках. Ми застосували однакові пороги, щоб перевірити стійкість моделі в реальному контексті. Оптимальна модель була обрана на основі порогової оцінки продуктивності, що забезпечує найкращу діагностичну корисність для клінічного використання. Для детальних розрахунків показників при різних порогах зверніться до додаткового онлайн -вмісту.
Поглиблений аналіз точності моделі у наборі зовнішньої перевірки: ретельне дослідження справжніх негативних та хибних позитивних зразків
Після оцінки моделі відносно низька точність набору зовнішньої перевірки сприяла більш глибокому дослідженню причин помилок, особливо зосереджено на справжніх негативах (TN) та помилкових позитивах (FP). Для визначення факторів, що сприяють цим помилковим класифікаціям, ми вибрали модель з найнижчим пропущеним рівнем діагнозу для подальшого аналізу. Ми витягнули зразки TN (здорові особи правильно класифікували як не-Met) та зразки FP (осіб без METS, але неправильно прогнозувались як позитивні) із зовнішнього набору D2. Ці зразки аналізували на основі п’яти ключових діагностичних критеріїв: WC, артеріальний тиск, ЛПВЩ-С, ТГ та ФБГ. Мета полягала в тому, щоб визначити характеристики даних, що призводять до неправильної класифікації та надання розуміння оптимізації моделі, підвищення її клінічної застосовності для ранньої діагностики та профілактики METS.
Програмне забезпечення та статистичні методи
Всі статистичні аналізи проводили за допомогою Python 3.8. Для безперервних змінних з перекошеними розподілами ми повідомили про медіану та міжквартильний діапазон (IQR, М (Q1, Q3)), хоча для нормально розподілених змінних ми представили середнє ± стандартне відхилення. Категоричні змінні виражалися як кількість та відсотки. Окрема логістична регресія була проведена для порівняння BRI та ІМТ, виходячи з їх актуальності в оцінці ризику METS. Для групового порівняння тест Манна-Вітні U використовувався для безперервних змінних із перекошеними розподілами та тестом Chi-квадрата для категоричних змінних. Попередня обробка даних та вибір функцій проводили за допомогою бібліотеки Pandas, а стандартизація даних проводилася за допомогою стандартів Scikit-Learn, щоб забезпечити узгодженість у масштабах функцій. Для вирішення дисбалансу класу ми використовували параметр Scale_pos_ ваги в класифікаторах для коригування фокусу на класі меншин, покращення продуктивності моделі та зменшення помилкових негативів. Статистична значимість була встановлена на P-значення 27, 28]. Заповнений контрольний список TripoD-AI був наданий як додатковий матеріал (додатковий файл 2).



