






TLDR: VISTA — це платформа з кількома агентами, яка покращує генерацію тексту у відео під час обговорення, планує структуровані підказки як сцени, проводить попарний турнір для вибору найкращого кандидата, використовує спеціалізованих суддів щодо зображення, аудіо та контексту, а потім переписує підказку за допомогою Deep Thinking Prompting Agent, метод показує послідовні переваги над сильними базовими лініями оптимізації підказок у налаштуваннях однієї сцени та кількох сцен, а оцінювачі віддають перевагу його результатам.
Що таке VISTA?
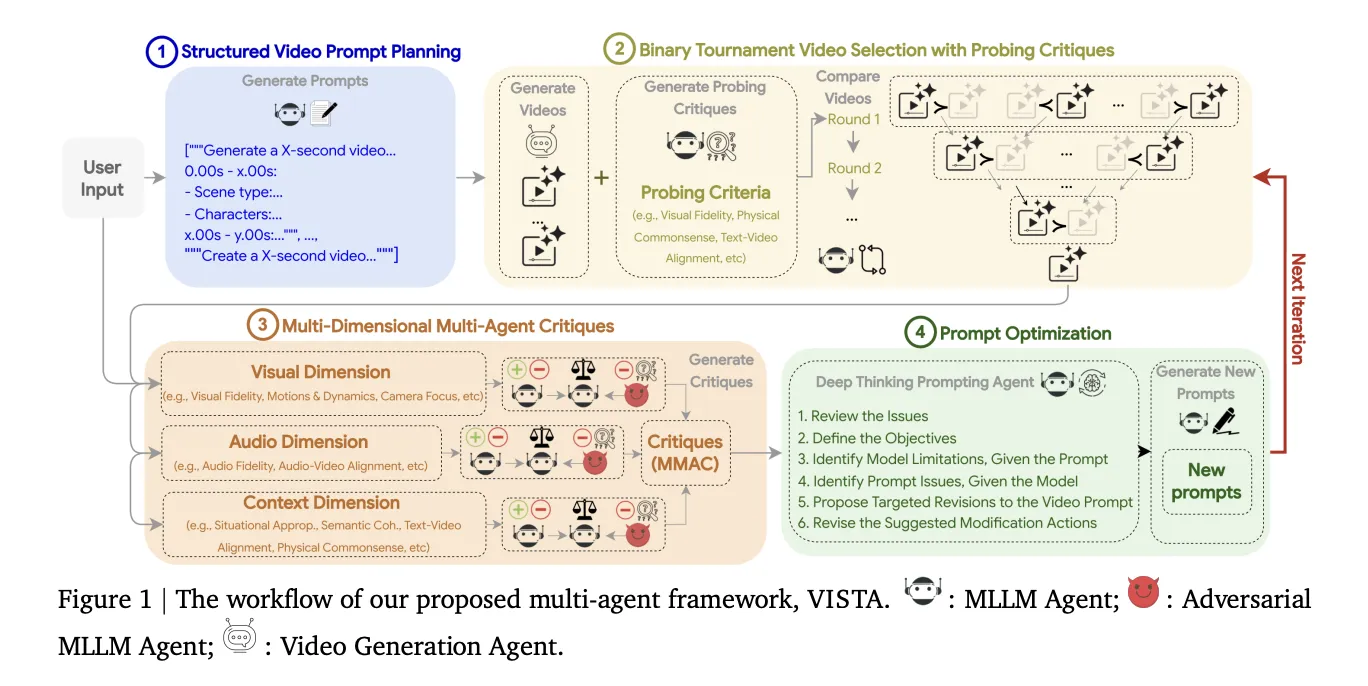
VISTA означає Video Iterative Self improvment Agent. Це чорний ящик, багатоагентний цикл, який уточнює підказки та відновлює відео під час тестування. Система націлена на 3 аспекти разом: візуальний, звуковий і контекстний. Він включає 4 кроки, структуроване планування відеозаписів, вибір парних турнірів, багатовимірну критику кількох агентів і агент підказок глибокого мислення для швидкого переписування.
Дослідницька група оцінює VISTA за тестом на одній сцені та на внутрішньому наборі кількох сцен. Він повідомляє про постійні покращення та до 60 відсотків парних виграшів порівняно з найсучаснішими базовими показниками в деяких налаштуваннях, а також 66,4 відсотка переваги людини над найсильнішою базовою лінією.

Розуміння ключової проблеми
Моделі «Текст у відео», як-от Veo 3, можуть створювати високоякісні відео та аудіо, але виходи залишаються чутливими до точного швидкого формулювання, дотримання фізичних принципів може виявитися невдалим, а узгодження з цілями користувача може відхилятися, що змушує вручну пробувати та помилятися. VISTA розглядає це як проблему оптимізації часу тестування. Він прагне уніфікованого вдосконалення візуальних сигналів, аудіосигналів і контекстного вирівнювання.
Як працює VISTA, крок за кроком?
Крок 1: швидке планування структурованого відео
Підказка користувача розкладається на тимчасові сцени. Кожна сцена містить 9 властивостей, тривалість, тип сцени, персонажів, дії, діалоги, візуальне середовище, камеру, звуки, настрій. Мультимодальний LLM заповнює відсутні властивості та накладає обмеження на реалістичність, релевантність і креативність за замовчуванням. Система також зберігає вихідну підказку користувача в наборі кандидатів, щоб дозволити моделі, які не мають переваг від декомпозиції.
Крок 2: вибір відео попарного турніру
Система вибирає декілька відео, підказує пари. MLLM діє як суддя з бінарними турнірами та двонаправленим обміном, щоб зменшити упередженість порядку токенів. Критерії за замовчуванням включають візуальну точність, фізичний здоровий глузд, вирівнювання текстового відео, вирівнювання аудіо, відео та взаємодію. Метод спочатку викликає дослідницьку критику для підтримки аналізу, потім виконує попарне порівняння та застосовує настроювані штрафи для загальних помилок тексту до відео.
Крок 3: багатовимірна багатоагентна критика
Чемпіонське відео та підказка отримують критику в трьох вимірах: візуальному, звуковому та контекстному. Кожен вимір використовує тріаду, звичайного суддю, змагального суддю та мета-суддю, який об’єднує обидві сторони. Показники включають візуальну точність, рухи та динаміку, узгодженість у часі, фокус камери та візуальну безпеку для зображення, точність аудіо, вирівнювання аудіо-відео та безпеку аудіо для аудіо, відповідність ситуації, семантичну когерентність, вирівнювання текстового відео, фізичний здоровий глузд, залученість та формат відео для контексту. Оцінки за шкалою від 1 до 10, що підтримує цілеспрямоване виявлення помилок.
Крок 4: Спонукальний агент глибокого мислення
Модуль міркування зчитує метакритику та виконує 6-етапну інтроспекцію, визначає показники з низьким балом, уточнює очікувані результати, перевіряє достатність підказок, відокремлює обмеження моделі від проблем із підказками, виявляє конфлікти чи нечіткість, пропонує дії щодо модифікації, а потім відбирає уточнені підказки для циклу наступного покоління.

Розуміння результатів
Автоматичне оцінювання: дослідницьке дослідження повідомляє про коефіцієнти виграшів, нічиїх і поразок за десятьма критеріями, використовуючи MLLM як суддю, з двосторонніми порівняннями. VISTA досягає коефіцієнта виграшу в порівнянні з прямими підказками, який зростає через ітерації, досягаючи 45,9 відсотка в одній сцені та 46,3 відсотка в мультисцені на ітерації 5. Він також виграє безпосередньо в порівнянні з кожною базовою лінією за того самого бюджету обчислень.
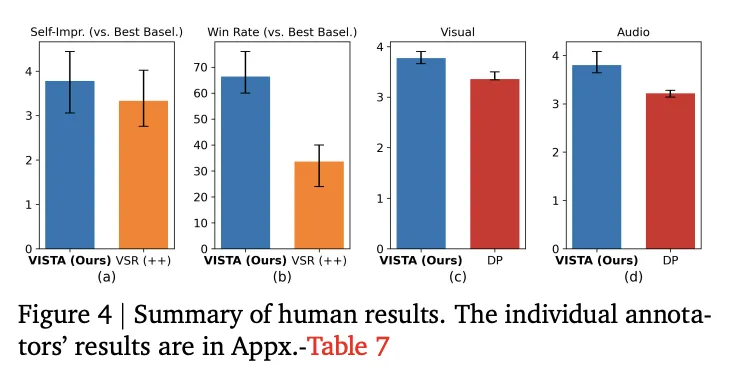
Дослідження людини: Анотатори з досвідом швидкої оптимізації віддають перевагу VISTA в 66,4 відсотках прямих випробувань порівняно з найкращою базовою лінією на ітерації 5. Експерти оцінюють траєкторії оптимізації вище для VISTA, і вони оцінюють якість зображення та якість звуку вище, ніж прямі підказки.
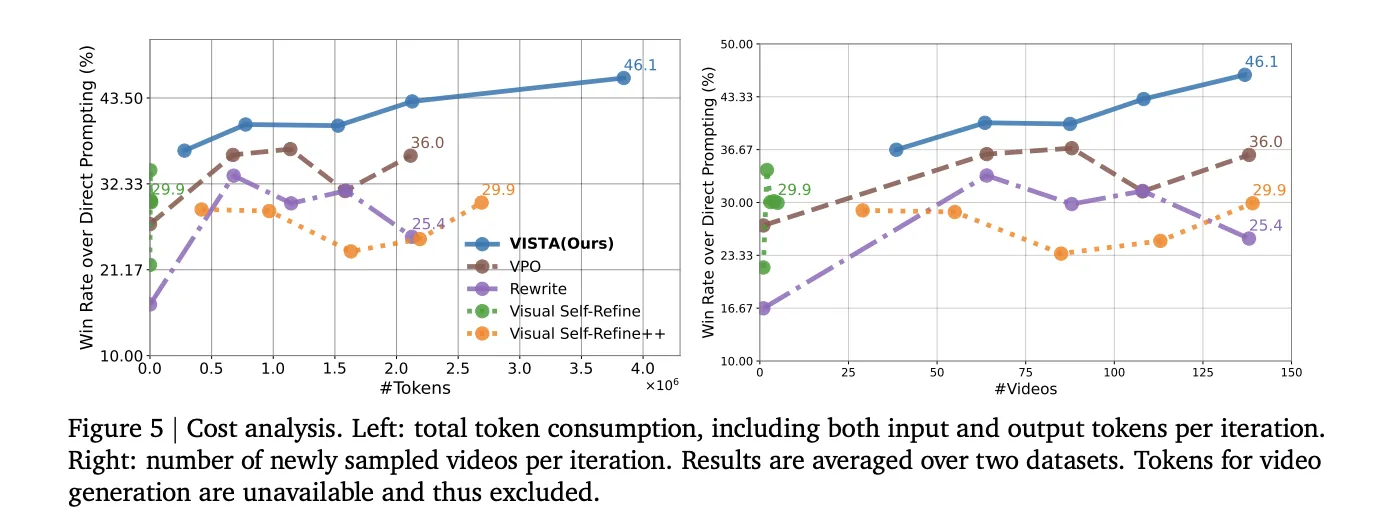
Вартість і масштабування: середня кількість токенів на ітерацію становить близько 0,7 мільйона в двох наборах даних, токени генерації не враховуються. Більшість використання токенів походить від відбору та критики, які обробляють відео як довгі контекстні введення. Коефіцієнт виграшу має тенденцію до зростання зі збільшенням кількості вибіркових відео та токенів за ітерацію.
Абляції: видалення оперативного планування послаблює ініціалізацію. Видалення вибору турніру дестабілізує наступні ітерації. Використання лише одного типу судді знижує продуктивність. Видалення Deep Thinking Prompting Agent знижує кінцевий коефіцієнт виграшу.
Оцінювачі: дослідницька група повторила оцінку за допомогою альтернативних моделей оцінювачів і спостерігала за подібними ітеративними вдосконаленнями, що підтверджує надійність тенденції.
Ключові висновки
- VISTA — це тестовий цикл із кількома агентами, який спільно оптимізує зображення, аудіо та контекст для створення тексту у відео.
- Він планує підказки як синхронізовані сцени з 9 атрибутами, тривалістю, типом сцени, персонажами, діями, діалогами, візуальним середовищем, камерою, звуками, настроями.
- Відео-претенденти обираються за допомогою парних турнірів за допомогою судді MLLM із двонаправленою перестановкою, оцінкою за точністю зображення, фізичним розумом, вирівнюванням текстового відео, вирівнювання аудіо-відео та залученістю.
- Тріада суддів на вимір, звичайний, змагальний, мета, дає від 1 до 10 балів, які скеровують Deep Thinking Prompting Agent переписати підказку та повторити її.
- Результати показують 45,9 відсотка перемог на одній сцені та 46,3 відсотка на кількох сценах на ітерації 5 порівняно з прямими підказками, люди-оцінювачі віддають перевагу VISTA в 66,4 відсотках випробувань, середня вартість жетонів на ітерацію становить близько 0,7 мільйона.
VISTA — це практичний крок до надійного генерування тексту у відео, він розглядає висновок як цикл оптимізації та зберігає генератор як чорний ящик. Структуроване планування підказок відео є корисним для ранніх інженерів, 9 атрибутів сцени дають конкретний контрольний список. Попарний вибір турніру з мультимодальним суддею LLM і двонаправленим обміном є розумним способом зменшити упередженість порядку, критерії спрямовані на реальні режими невдачі, візуальну точність, фізичний здоровий глузд, вирівнювання текстового відео, аудіо-відео вирівнювання, залучення. Багатовимірна критика розділяє зображення, аудіо та контекст, звичайні, суперницькі та мета-судді виявляють слабкі сторони, які окремі судді пропускають. Deep Thinking Prompting Agent перетворює цю діагностику на цільові редагування підказок. Використання Gemini 2.5 Flash і Veo 3 уточнює еталонну настройку, дослідження Veo 2 є корисною нижньою межею. Повідомлені показники виграшів у 45,9 і 46,3 відсотка та 66,4 відсотка переваги людей вказують на повторювані успіхи. Вартість 0,7 мільйона токенів є нетривіальною, але прозорою та масштабованою.
Перевірте Папір і Сторінка проекту. Не соромтеся перевірити наш Сторінка GitHub для посібників, кодів і блокнотів. Також не соромтеся слідкувати за нами Twitter і не забудьте приєднатися до нас 100k+ ML SubReddit і підписатися на наш інформаційний бюлетень. Почекай! ти в телеграмі? тепер ви також можете приєднатися до нас у Telegram.
Асіф Раззак є генеральним директором Marktechpost Media Inc. Як далекоглядний підприємець та інженер, Асіф прагне використовувати потенціал штучного інтелекту для суспільного блага. Його останньою ініціативою є запуск медіа-платформи штучного інтелекту Marktechpost, яка виділяється своїм глибоким висвітленням новин про машинне навчання та глибоке навчання, які є технічно надійними та легко зрозумілими широкій аудиторії. Платформа може похвалитися понад 2 мільйонами переглядів на місяць, що свідчить про її популярність серед аудиторії.
🙌 Слідкуйте за MARKTECHPOST: додайте нас як бажане джерело в Google.



