






Використання LLM для допомоги в організації саміту інформатики AMIA 2024 підкреслює їх потенціал для підтримки та посилення прийняття рішень людини в академічних умовах. Автоматизуючи рутинні та складні завдання з обробки даних, LLMS звільнив організаторів та відвідувачів, щоб глибше взаємодіяти з суттєвим змістом конференції. Це покращена логістична ефективність та академічний дискурс під час конференції, забезпечивши тематичну узгодженість та полегшення навігації конференції.
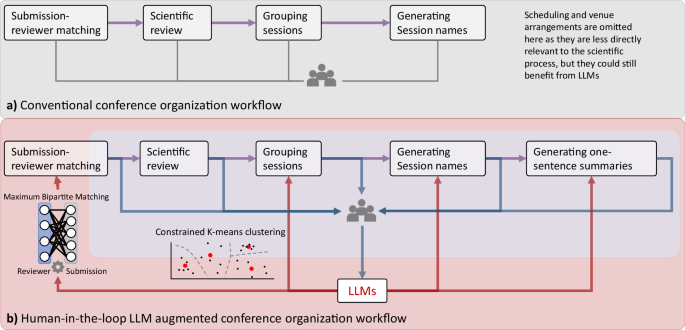
Ми продемонстрували, що можна використовувати LLMS для встановлення системи відповідності подання рецензентів із індивідуальними вимогами та вирішили наступні обмеження за допомогою підходу людини в циклі. По-перше, використання лише доменів електронної пошти може не повністю фіксувати потенційні конфлікти, особливо коли рецензенти чи автори використовують особисті адреси електронної пошти або коли співпраці співпраці не є безпосередньо доступними. Для вирішення цього обмеження ми впровадили багатоступеневий підхід, що входить до циклу, для зміцнення гарантій COI. По-перше, після застосування автоматизованого виключення на основі домену електронної пошти ми включили крок вручну огляд, де організатори оцінювали матчі, щоб визначити будь-які потенційні конфлікти, пропущені автоматизованим процесом. Крім того, рецензентам було запропоновано визначити та розкрити будь -які конфлікти для призначених їм робіт, що було традиційним способом виявлення конфліктів на попередніх конференціях AMIA. Наш шаруватим підходом людини в циклі забезпечує збалансовану стратегію, яка поєднує автоматизовану ефективність з людським судженням, щоб краще забезпечити дотримання COI. По-друге, експертиза рецензентів у нашому процесі відповідності базувалася на ключові слова, про які повідомлялося. Протягом більш ніж десятиліття AMIA підтримує пул рецензентів та ключових слів, які постійно оновлюються, зберігаючи тих рецензентів, які демонструють продуктивність та надійність, про що свідчать їх чуйність та якість у перегляді завдань, узгоджених з їхніми ключовими словами, що повідомляються в попередні роки. Хоча цей підхід виявився ефективним, ми визнаємо його обмеження, оскільки точність завдань рецензентів по суті залежить від точності та актуальності повідомлених ключових слів. Щоб вирішити це, ми включили процес людини в циклі, де організатори конференції переглянули автоматизовані матчі, влаштувавши корективи за потребою для забезпечення оптимальних завдань рецензента. Це поєднання експертизи, проведеного з самозвіту, відповідності даних та контролю людини, є збалансованим підходом і відповідає найкращим практикам у цій галузі.
Тематичне угруповання презентацій, що працюють від LLMS, дозволило створити інтелектуально стимулюючі та контекстно релевантні сеанси. Ефективно захоплюючи суть та тематичні зв’язки академічних робіт, LLMS сприяла створенню сесій, що резонували із передбачуваними підтемами конференції. Більше того, добровільні відгуки від багатьох відвідувачів під час конференції вказували на те, що підсумки одного речення покращили їхній досвід. Зокрема, відвідувачі зазначили, що ці стислі підсумки легко читати на мобільних пристроях та забезпечували швидке розуміння порівняно з читанням повних тез, допомагаючи їм більш ефективно вирішити, які сесії відвідувати. В майбутньому необхідна систематична оцінка потенційних переваг автоматизованого підходу до узагальнення одного речення на мультидисциплінарних конференціях, щоб визначити, як найкраще допомагати учасникам у навігації одночасних сесій.
Рівень втручання людини, необхідний для LLMS, змінюється в різних завданнях. Групування презентацій та плакатів у тематичні сесії вимагали найбільш людського нагляду. Для зіставлення подання-ревізії, поетапна ланцюгова спонукання допомогло вибрати основний алгоритм, визначити структуру даних, кодувати обмеження та впровадити обраний алгоритм, використовуючи відповідні пакети. Це призвело до ефективних матчів без скарг рецензентів. Генерування підсумків одного речення вимагало мінімального перегляду людини, оскільки організатори виявили, що LLMS створює хороші підсумки. Хоча логістичні обмеження запобігали тестуванню A/B, ми можемо забезпечити розрахункове порівняння на основі нашого досвіду. Використовуючи підхід, що підтримує LLM, спонукаючи Chatgpt генерувати код Python для відповідності рецензентів, огляду та запуску, він зайняв близько 30 хвилин. На відміну від традиційного ручного підходу під час саміту інформатики AMIA в попередньому році (трохи менший за розмірами), необхідний понад 20 год (Ілуо був віце -кріслом). Для групування презентацій на сеанси написання та виконання коду Python за допомогою API OpenAI зайняли близько 30 хв, з додатковими двома годинами організаторів для вдосконалення назв групування та сесій. Для порівняння, створення групів сеансів вручну для саміту попереднього року зайняло приблизно 2,5 дні. Аналогічно, генерування підсумків одного речення для презентацій за допомогою підходу, що підтримується LLM, потрібно було близько 15 хв для запису та виконання коду Python. Уручну узагальнено 150 презентацій – встановлення 10 хв за резюме – займе приблизно 25 год. Під час розщеплення та перегляду підсумків, що створюються LLM, додали близько двох годин для авторів, цей процес огляду може бути делегований відповідним авторам на майбутніх конференціях, що додатково розповсюджуючи вартість часу. Ці порівняння підкреслюють значну економію часу за допомогою підходу, що підтримує LLM, показуючи потенціал як ефективну альтернативу традиційним методам.
Для завдання групування презентацій та плакатів у тематичні сесії ми оцінили послідовність результатів кластеризації з двох LLM, використовуючи різні входи (заголовки, тези та ключові слова). Через обмеження логістичної та часової шкали, притаманні організації конференції, ми не змогли вичерпно перевірити всі можливі конфігурації та перестановку для кожного LLM. Натомість ми зосередилися на обмеженому наборі конфігурацій введення з практичним значенням для моделей GPT та LLAMA. У таблиці 1 видно, що наші моделі на основі GPT були більш узгоджені з різними входами порівняно з моделями LLAMA, які показали низьку узгодженість. Найвища узгодженість для GPT була між входами титулу та абстракту та титул-абстракт-ключем, але навіть це було скромно, що свідчить про чутливість до введення та необхідність перегляду людини. Виходячи з цих порівнянь-і після консенсусу серед крісел та віце-крісел-ми виявили, що результати на основі ГПТ, як правило, кращі для наших конкретних потреб. Однак ми визнаємо, що цей висновок обмежений обсягом нашого порівняння і підлягає конкретним уподобанням та організаційному контексту цієї конференції.
Організатори обрали кластеризацію титулу та абстмарного за допомогою GPT після огляду. Додавання ключових слів іноді призводили до загальних угруповань, тоді як за винятком їх зберігання більш конкретно. Наприклад, дослідження трансгендерних популяцій у педіатричній психіатрії, позначеному ключовими словами соціальних детермінантів здоров'я (SDOH), орієнтованим на характеристику даних EHR субпопуляцій, а не на самі SDOH. Подальші вдосконалення були зроблені для кластеризації GPT. Наприклад, кілька сеансів щодо обробки природних мов (NLP) потребували реорганізації в підтемах, таких як моделі мови охорони здоров'я та дослідження, орієнтовані на GPT. Заключні сеанси показали скориговану взаємну інформацію (AMI) 0,6041 з пропозиціями GPT, яка була вищою, ніж AMIS серед усіх сеансів, що генеруються LLM, підкреслюючи важливість, що хороша вихідна точка, що надається LLM, може сприяти налагодженню людини.
Для багатьох назв сеансів, що надаються GPT, ми безпосередньо прийняли пропозиції, такі як “розширення можливостей клінічних НЛП з великими мовними моделями” та “SDOH: розуміння, інтерпретації та інновації”. Однак деякі сеанси вимагали більшого вкладу людини, щоб забезпечити, щоб назви точно відображали різноманітність їх змісту. Наприклад, ми змінили “підвищення взаємодії та підтримку клінічних рішень за допомогою FHIR” на “підвищення взаємодії в охороні здоров'я”, оскільки не всі презентації в цій сесії, зосереджені на FHIR (швидкі ресурси сумісності охорони здоров'я) та підтримку клінічних рішень. Це гарантувало, що назви сесій були всеосяжними та репрезентативними для їх відповідних презентацій. Для оцінки подібності між списками назв сеансів до та після модифікації людини ми використовуємо моделі вбудовування GPT для створення векторних представлень кожного імені сеансу в обох списках. Порівнюючи схожість косинусу між цими векторами, ми знайшли найближчу відповідність для кожного імені сеансу в одному списку до імені сеансу в іншому списку. Середній показник цих подібностей на всіх сесіях мав числовий показник подібності 0,9334, демонструючи, що мінімальні корективи вважаються необхідними.
Підсумовуючи це, ця робота є ранніми зусиллями щодо інтеграції LLM в процес організації конференції, надаючи цінні уроки для майбутніх академічних конференцій, спрямованих на поєднання людських знань з обчислювальною силою LLM. Наш підхід є масштабованим та пристосованим для використання ШІ в академічних умовах, в кінцевому рахунку сприяє більш ефективній та спільній спільноті. Незважаючи на те, що LLM значно розширили автоматизацію організаційних конференц-організацій, таких як відповідність піддань та генеруючи резюме з одного речення, людський нагляд залишається важливим, особливо в групуванні презентацій у тематичні сесії. Повна автоматизація створення порядку денного конференції з мінімальним вкладом людини вимагає більш ітеративних подій, постійного уточнення та широкого тестування, оскільки моделі AI стають більш досконалими.



