







Yelp посилив свій тренінг з машинного навчання та досягнув a 1400-кратне прискорення використовуючи комбінацію TensorFlow, Horovod та їх спеціального ArrowStreamServer. Вони перейшли з Petastorm на більш ефективне рішення потокового передавання даних, оптимізували масштабування GPU та покращили пакетну обробку. Ось як вони це зробили.
Потрібно вирішити Yelp. Моделі рейтингу переходів оголошень (pCTR) Yelp працюють на масивних табличних наборах даних, які зберігаються у форматі Parquet на S3. Спочатку підготовка взяла 450 мільйонів проб 75 годин на епоху на одному екземплярі GPU. Зростаючи дані до 2 мільярдів зразків, вони прагнули зменшити час навчання до 1 години на епохустикаючись з ключовими викликами:
-
Неефективна передача даних: Повторне пакетування Petastorm викликало проблеми з продуктивністю.
-
Масштабування використання GPU: MirroredStrategy від TensorFlow не вдалося ефективно масштабувати понад 4 GPU.
-
Управління обчислювальними ресурсами: Проблеми з потоками призвели до вузьких місць продуктивності та надмірного використання пам’яті.
1️⃣ Ефективне потокове передавання даних за допомогою ArrowStreamServer
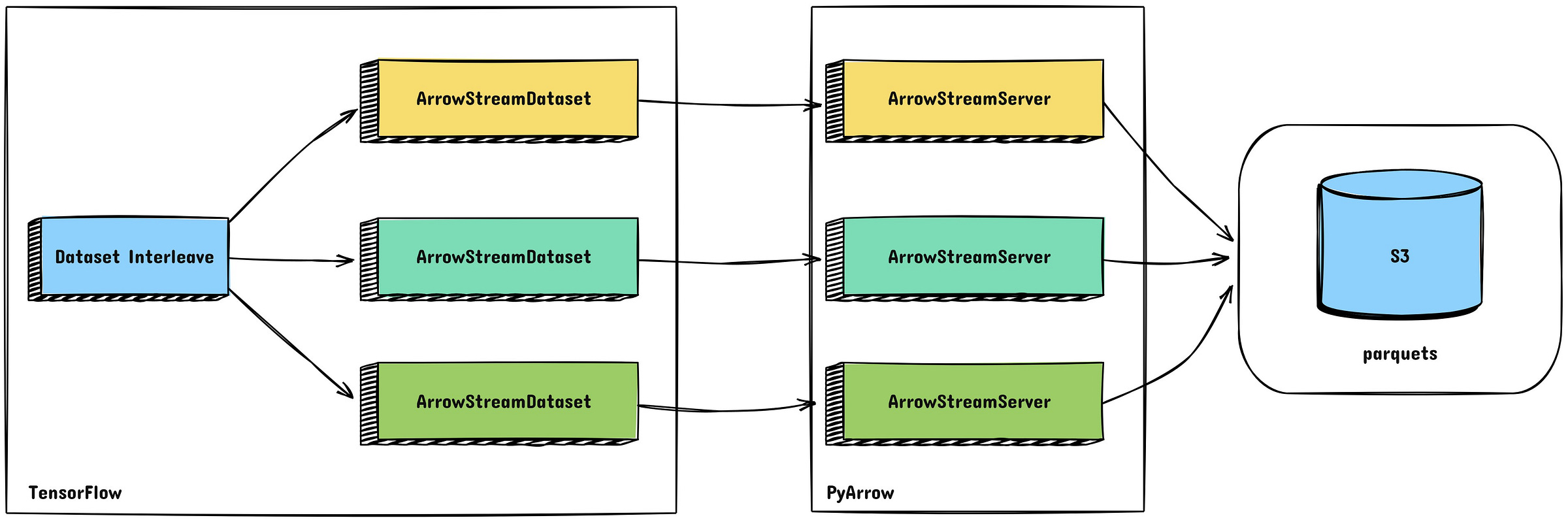
Спочатку використовувався Petastorm, але він мав проблеми зі складністю повторного пакетування табличних даних. Yelp розроблений ArrowStreamServerспеціальне рішення на основі PyArrow, яке:
-
Передає дані з S3 оптимізованими пакетами.
-
Усуває неефективність генераторів Python.
-
Використовує потокове передавання RecordBatch для швидшого використання TensorFlow.
-
Забезпечує гнучкість для масштабування великих наборів даних, зберігаючи низьку затримку.
Підвищення продуктивності:

Перемикаючись на ArrowStreamServer, Yelp досягла 85,8-кратного прискорення у потоковій передачі даних.
2️⃣ Масштабування за допомогою Horovod для розподіленого навчання
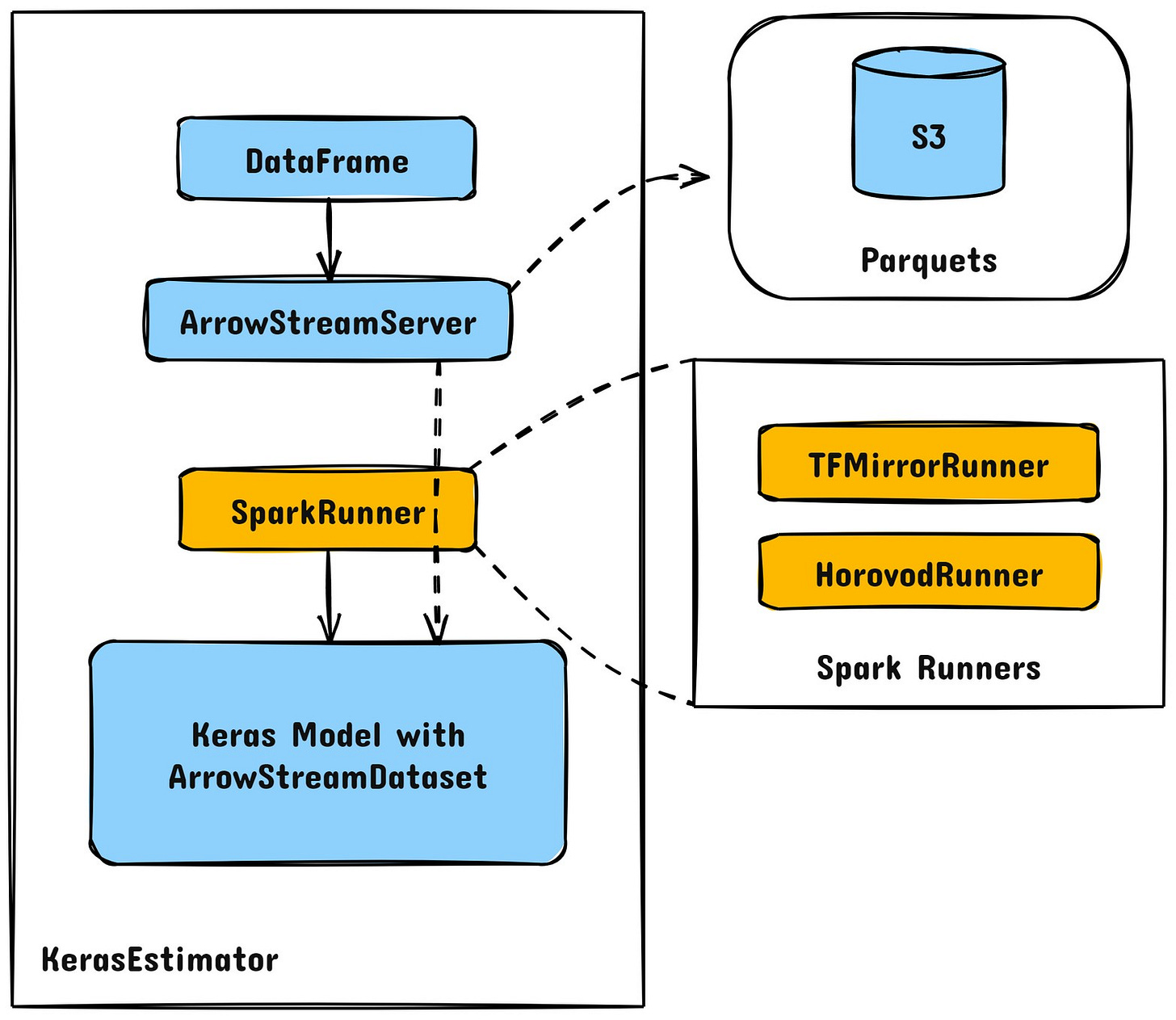
MirroredStrategy від TensorFlow забезпечила меншу віддачу понад 4 GPU через неефективність сегментування набору даних. Yelp переїхав до Horovodщо дозволило:
-
Лінійне масштабування до 8 GPU.
-
Більш ефективне використання ресурсів з одним процесом на пристрій.
-
Ефективне перетворення градієнта з розрідженого на щільний.
-
Повна відмовостійкість із можливостями еластичного навчання.
Цей перехід призвів до а 16,9-кратне підвищення швидкості навчання моделі.
-
Потокові бурі: Тисячі тем спричинили надмірну підписку. Вони вирішили це, налаштувавши параметри потоків TensorFlow для кожного GPU:
-
private_threadpool_size = CPU cores per GPU -
ram_budget = Available host memory per GPU -
OMP_NUM_THREADS = CPU cores per GPU
-
-
Жорстка сумісність: Yelp довелося перевизначити
train_stepWideDeepModel для забезпечення сумісності з розподіленим оптимізатором Horovod. -
Вузькі місця каналу даних: Перехід від конвеєра даних, орієнтованого на пакетну роботу, до конвеєра, орієнтованого на потокову передачу даних, вимагав переосмислення вхідного конвеєра, гарантуючи, що дані подаються зі швидкістю, яка повністю використовує потужність GPU без затримки.
-
Контрольні точки та відновлення: З розподіленим навчанням контрольно-пропускні пункти стали складнішими. Yelp реалізував надійний механізм контрольних точок, щоб забезпечити узгодженість стану моделі для кількох робочих місць у разі збоїв.
🌟 Результати: швидше навчання та менші витрати Завдяки оптимізованому потоковому передаванню даних і розподіленому навчанню Yelp зменшив час навчання з Від 75 годин до менше 1 годинидосягнувши заг 1400-кратне прискорення.



